



The introduction of artificial intelligence (AI) and large language models (LLMs) has resulted in massive changes in the world of work, with expected ongoing shifts into the future.[1] AI is novel in that, unlike all previous innovations, whatever further complexity it creates does not necessarily have to be solved by a human being, as it is a solution engine.[2] However, it is not a novelty engine in the way human beings are, since it has no independent agency.[3] What is happening, however, is that we are rewarding individuals who use AI as if they had created wholly original work.[4] This has been done by using our prior notions of how to determine originality and provenance to assign ownership and credit, which form the basis of how we remunerate and incentivize the creation of intellectual property (IP).[5] The issue with these outdated notions, developed to be applied to a value chain of knowledge featuring only intentional ideation (and thus informed actors), is that, in the current climate, we are undermining the incentive mechanisms for ideators. As it weakens, so does the drive to work through the difficulty of creation.[6]
The data value chain contains the AI process within it now, placing an extra step between the intentional ideators, which involves unclear recombination of ideas from innumerable sources. Yet beneath these advances lies a quiet crisis—the large-scale, often invisible theft of human IP through AI’s frictionless recombination of existing intellectual work.[7] To determine credit under this new paradigm, we must accept that the inclusion of AI makes IP provenance uncertain.[8]
Our issue stems from confusing the tool with the creator. Despite food coming from a kitchen, it is not made by it—it is made by chefs, who constitute the kitchen. Likewise, AI does not create but assembles human-made inputs. Thinking otherwise is a fallacy. Interventions must target humans. To ensure we continue to compensate creatives for novel ideas, ensuring their continued creation, we must construct a statistical notion of accreditation to accommodate the new AI phase of ideation.
This paper presents a design framework placing statistically driven remuneration as a means of ensuring long-term societal productivity, specifically for expanding the accessible AI systems solution space. The study is divided as follows: This article first discusses what currentissues in the world today necessitate such innovation. Then I explain the expectations for the future of work and exactly why AI may not mean more jobs. This problem is demonstrated in an introduction to the concept of agency and its association with the ideation process. I then illustrate the impact of this on the difference between AI and AGI by explaining how AI works and the unique advances of LLMs. With this, I explain the importance of addressing reward mechanisms for sustainable human integration to ensure human-AI alignment. To define what sort of step-change this would involve, I introduce the framework of the “classical intentional” and “modern statistical” IP paradigms. The importance of taking this step toward statistical IP ownership and the remuneration that it would bring to the world is then discussed. I conclude by outlining how such a system would look and discussing its implications and next steps.
Problems in the World Today
The job market has shrunk dramatically this year, with hiring rates in the USA, for example, more than 20% below pre-pandemic levels[9] and global job gaps, defined as the number of people who would like a job but currently do not have one, are estimated to reach 407 million people in 2025.[10] This is manifesting as a drop in global employment growth rates from 1.7% in 2024 to 1.5% in 2025.[11] The World Economic Forum finds that 40% of employers are planning to reduce staff as their skills become less relevant as a consequence of AI.[12] Further to this, labor market studies show that young workers (age 22–25) in occupations highly exposed to AI automation have seen a ~6% employment decline between late 2022 and mid-2025.[13]
Entry-level or early-career positions focusing on routine tasks are disproportionately exposed to substitution: since ChatGPT’s launch, demand, supply, and transaction volumes have fallen most in text-related and programming submarkets, declining 22% with a 16% drop in private contractor bids, indicating meaningful displacement even 2 years ago.[14]
These disruptions in employment are not merely cyclical but structural, indicating that shifts in technology have begun to outpace the incentive systems that historically balanced innovation and labor.
The Future of Work
Historically, new innovations expanded the job market[15] by creating new complex tasks to deliver them,[16] but AI may break this trend. Its innovation is a scalable “solution engine”, so the complexity it introduces does not necessarily need to be handled by human beings,[17] meaning the expectation of net job growth is contested.[18]
With AI, what appears as productivity growth is often a hidden substitution of human creativity with unacknowledged reuse of existing intellectual labor—an economic displacement driven by informational theft rather than efficiency alone. This is because AI is not a single tool but a novel ecosystem of knowledge capture and processing.[19] In that sense, the ecosystem of AI is much akin to a new phenomenon, such as the weather or a biome. That is, rather than solely increasing the complexity of the work ecosystem, we generate a whole new “AI ecosystem”.
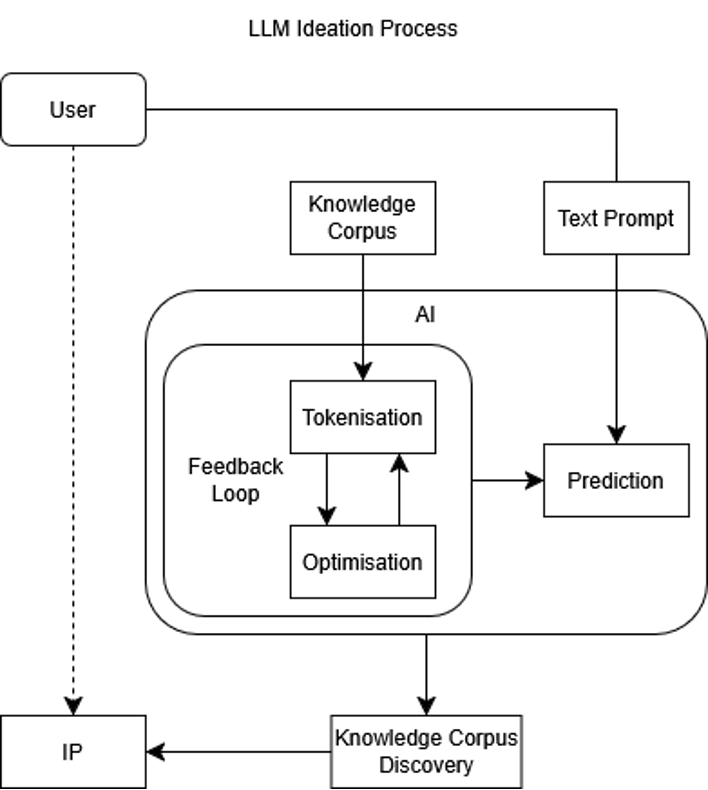
This ecosystem incorporates a distinct ideation space, where ideation occurs through automated recombination rather than direct human reasoning, as is the paradigm in real space. Humans in real space, who are embedded in the whole knowledge corpus, access the AI ideation space, embedded in a limited corpus. In this limited space, AI allows real space inhabitants to skip to ideas without traversing real space, by definition not having knowledge about the path there, thus perceiving it as automatic and opaque. This is depicted in Figure 1.
Stepping beyond the notion of ecosystems, it can be viewed as a space unto itself. As an analogy, traditionally, an ideator works upon the corpus of knowledge to create ideas within real space while existing in real space themselves. Under the AI ideation paradigm, an ideator wormholes through to the AI space, which only contains the corpus of knowledge the AI can engage with, and allows for ideation to be done there and returned into real space. Thus, the process of ideation, from the ideator’s perspective, becomes automatic and opaque. This is expressed in Figure 1 below.
To understand why AI’s impact on employment differs from previous technological shifts, we must examine how the concept of agency functions in the act of creation itself.
Figure 1
Agency and Ideation
In the creation of the AI ecosystem, we are developing an engine for idea creation whose flows we do not fully understand, such that solutions from AI are discovered rather than generated.[20] This is distinct from search engines, which are archival search tools, pointing to known knowledge. AI instead helps discover forms of knowledge from the corpus of human ideas. Despite this, AI is not a generator, as the ideas are not novel.[21]
For AI to create novelty, it needs to be a self-interested agent with unique goals. Humans both discover and create—consider calculus, invented by Newton[22] and Leibniz[23] independently. They were able to invent the same theoretical system, but they expressed it distinctly by their notations. That calculus was replicable suggests it was discovered; however, their notations not being so suggests they were created. To express calculus in their manner relied on their status as distinct and unique agents, which is why they approached the same problem distinctly. The division of creation and discovery is shown in Figure 2, with their synthesis exemplified by Newton and Leibniz in Figure 3.
Figure 2
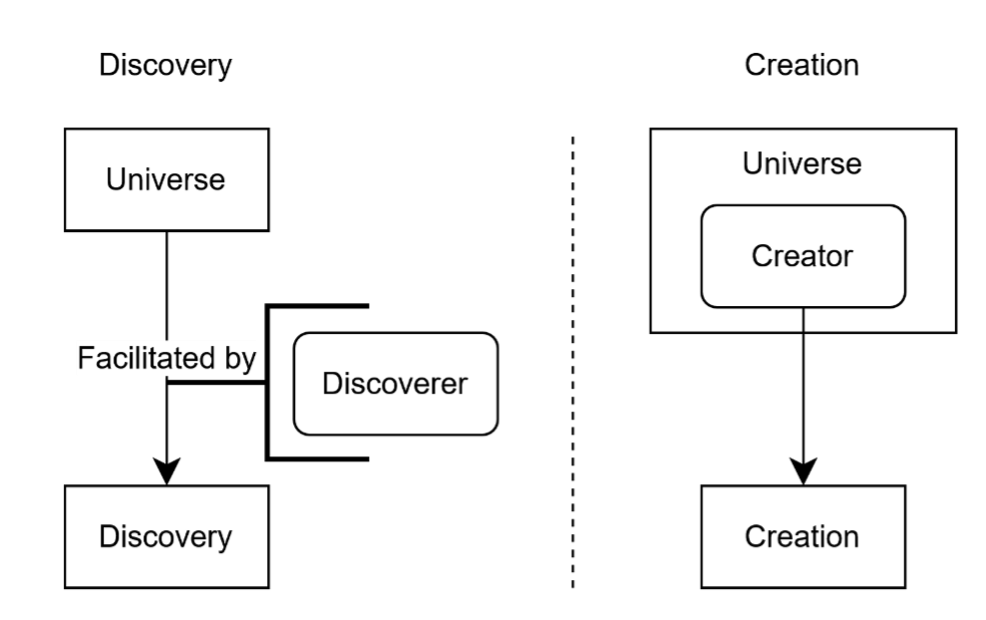
The universe has no agency, so discoveries such as calculus can be rediscovered. However, inventions, as they rely on agents, cannot be recreated in the same way.[24] Thus, we can (theoretically) invent calculus ourselves, and such processes—disprovability—are the basis for the scientific method, giving us the dichotomy of created IP versus discovered IP.[25]
Figure 3
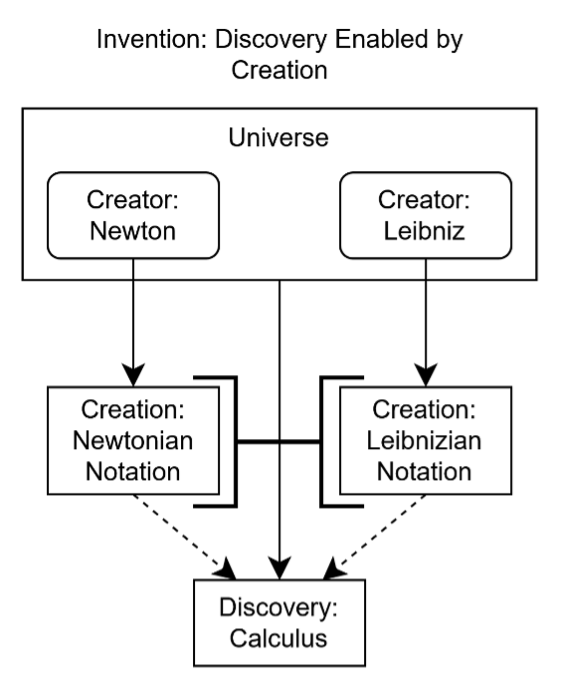
This study contends that, based on the idea that creation is made by those with agency, because AI platforms possess no agency, they are unable to create; they can only discover. This presents a huge problem, since that means the global overuse of AI is a distraction against novel ideation, thus disincentivizing us against ensuring the improvement of AI models and the corpus of human knowledge.
If creation depends on agency, then our legal systems for recognizing ownership must evolve to reflect who—or what—can truly be said to originate ideas.
How AI Works and How AGI Would Work
Practically, the great innovation of AI is the frictionless coupling of web-scale scraping, large-dataset modelling, and a chatbot interface. This has allowed laypeople to use powerful computation over much of the world’s knowledge with very low engagement or education, extending the problem-solving capability of anyone with internet access.[26]
This is distinct from the concept of AI, which has existed as a field of research since 1956, during the Dartmouth Summer Research Project on Artificial Intelligence,[27] or the artificial neural network, which is the basis upon which the major LLM models we use today are founded and was developed in 1958[28] by Frank Rosenblatt.
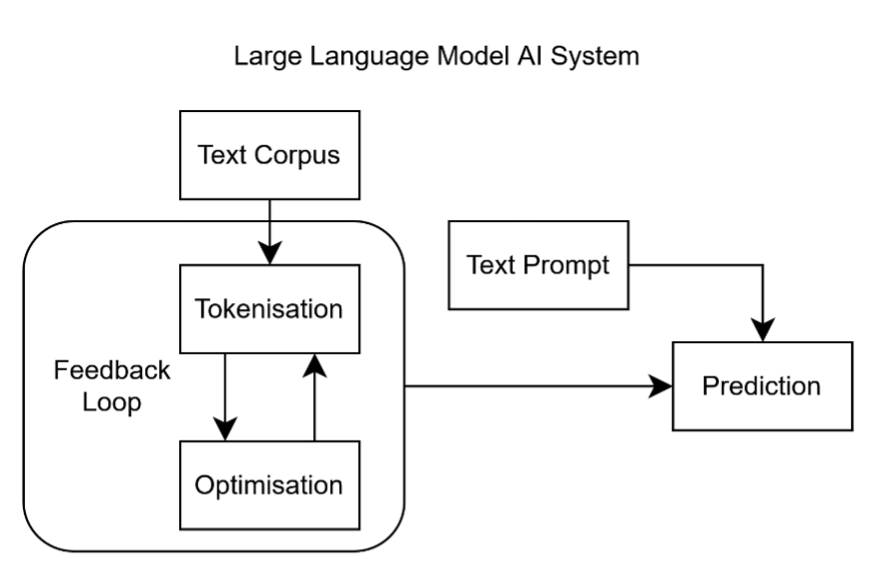
An AI algorithm is a structured set of mathematical and logical instructions operating on a dataset to extract information or reasoning through systematic computation and an internal mathematical feedback loop. Depicted in Figure 4, it typically involves:
- Input data (e.g., text, images, numbers);
- A model (a mathematical representation of relationships within that data);
- An optimization process (adjusting parameters to minimize error or maximize accuracy);
- Output (predictions, classifications, or actions).
Figure 4
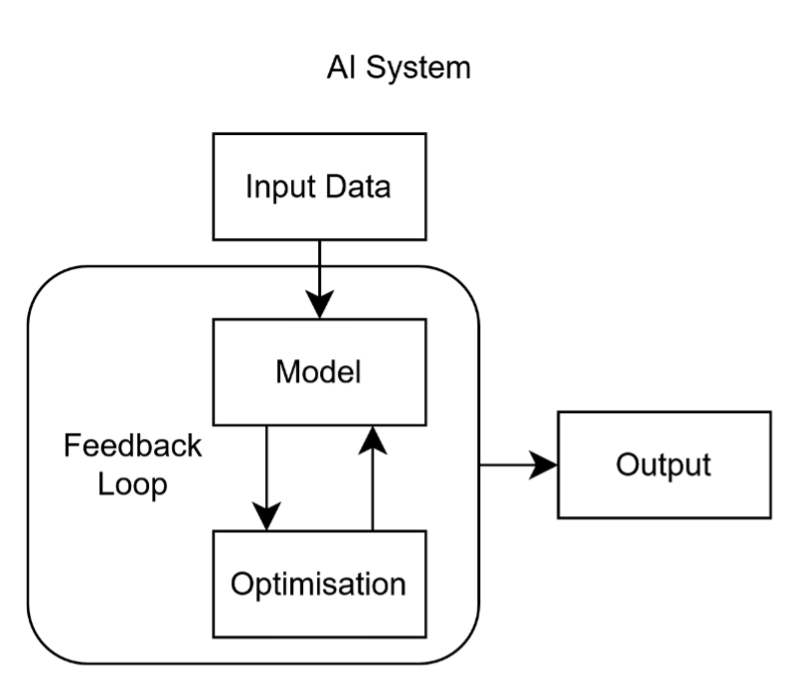
A human is not involved in the feedback loop, and statistical methods are used to generate each step of the loop up to the output. Thus, we are unaware of what the outcome of an AI would be before using it, and we do not know, with certainty, how an answer was obtained, though we have methods to predict and influence these to some accuracy.
An LLM is a particular type of AI model, which takes a large corpus of textual data, tokenizes parts of it at multiple scales (words, sentences, paragraphs, etc.), and, given a text string, learns to predict the next token. An example of this would be a text involving a question and answer—if trained on a sufficient number of questions and answers, an LLM can be fed a question and predict what the answer would be, offering up that prediction and completing the body of text. Expanding on Figure 4, this is shown in Figure 5. This is the basis of the chatbots and AI agents we use today.[29]
Figure 5
LLMs—so-called “generative” AIs—sample existing information, statistically discovering patterns in it. This can involve nearly all public datasets, with these patterns returned as outputs. No creation has occurred because the unique perspective of the models is not incorporated in the act of discovery, since the AIs have no unique perspective owing to their lack of independent goals.[30] Embedding the LLM process in Figure 5 to Discovery in Figure 2 returns Figure 6.
Figure 6
This has created a challenge for IP. Works created with AI are derivative; however, the AI process hides the sources of influence. Legally, such use often falls under fair use or open access, yet these frameworks were never designed for statistical recombination at scale. As a result, vast amounts of human-created material are absorbed without trace or credit, revealing a gap between ownership and use that demands quantitative attribution mechanisms.[31]
Genuine creativity requires independent goals and, for AI, would imply an artificial general intelligence (AGI). These goals would have to be distinct from our own to be independent, entering into an alignment problem, which could manifest as malicious AI.[32]
Old and New IP Paradigms
Preventing malicious AI that is more powerful than us requires eliminating incentives to build it.[33] Conveniently, humans are efficient and scalable generative and general intelligence—to paraphrase Paul Erdős, “a human is a machine for turning coffee into ideas”—so there is great reason to direct incentives to develop humanity. We, therefore, have reason to build mechanisms rewarding human creativity while integrating AI’s discovery role. This would allow future creative AI—or AGI—to coexist cooperatively with humanity rather than compete.
Intellectual property (IP) forms much of how we administer ideation remuneration. For IP, such as academic papers or patents, provenance is documented and verified through a peer review committee or patent office. Legal infrastructure exists around the world to administer IP transfer, determine ownership, punish legal infringements, and reward adherence.[34] Yet this system was never designed for the mass appropriation of creative work by autonomous systems, which now extract and reformulate ideas on a scale that effectively institutionalizes IP theft under the banner of fair use.
AI outputs are often treated as original, though they merely recombine existing material. Because no human selects the sources, their provenance—and rightful credit—cannot be verified within current IP frameworks.[35] Thus, we have a tool of a limited knowledge corpus and solution finders embedded in real space.[36]
This presents a breakdown of the concept of IP. Historically, when the difficulties of sustaining IP are too great to justify constructing the legal infrastructure to enable its protection, but the creator still wants to produce it, it would be released into the public domain or some similar construction where the creator relinquishes rights to ownership, stating that the broader public is the owner.[37] The issue with this is that it empowers AI agents to operate more effectively, as they chiefly sample from public domain data. This incentivizes individuals to more readily use AIs in their creation process as opposed to other people, despite the exclusion of a person, meaning it is not actually a creation, but a discovery process, and a discovery process of that which is already known. This creates a vicious cycle where we have more reason not to create and have less capacity to do so.[38]
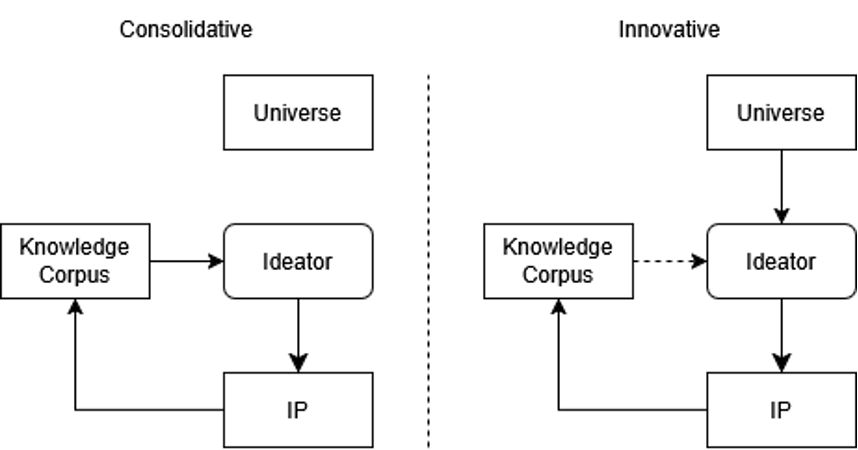
I propose a technological, statistically based IP paradigm that rewards genuine creativity and measures contribution to AI outputs probabilistically. This would replace today’s wicked consolidation cycle with a virtuous innovation cycle that aligns AI improvement with human innovation[39]—an applied form of creative destruction. This would then take control of the expansion of the public domain in a manner that makes humans and AI wholly cooperative entities, rather than competitive ones.[40] This is depicted in Figure 7, matching the Figure 2 discovery for consolidative economies and the Figure 2 creation for innovative economies.
Figure 7
The Value of Statistical Ownership
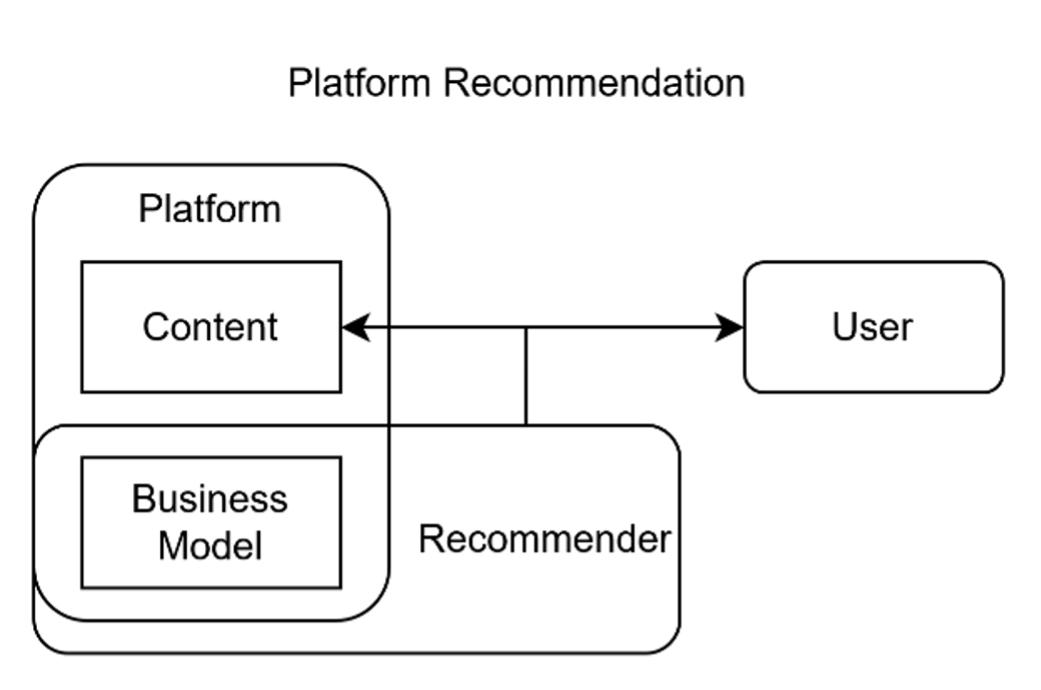
Statistical accreditation already exists in social media, where platforms promote content algorithmically according to its business value. This “statistical push” model directs remuneration from the platform to creators.[41] This presents a statistical push model, enabled by the platform owning the content and choosing who uses it, depicted in Figure 8. In this instance, remuneration comes from, generally, the platform to the content creators.[42]
Figure 8
Conversely, legal IP accreditation operates as an “intentional pull” model, mandated by IP not being owned by the legal entities managing it. Here, rights to use or ownership of IP are administered by legal entities for the interested parties, hinging on explicit determination of ownership. This presents an intentional pull paradigm, mandated by IP not being owned by the legal bodies handling it and clients generating cases, as depicted in Figure 9. In this instance, remuneration comes, generally, from the user of the IP to the owner of the IP.[43]
Figure 9
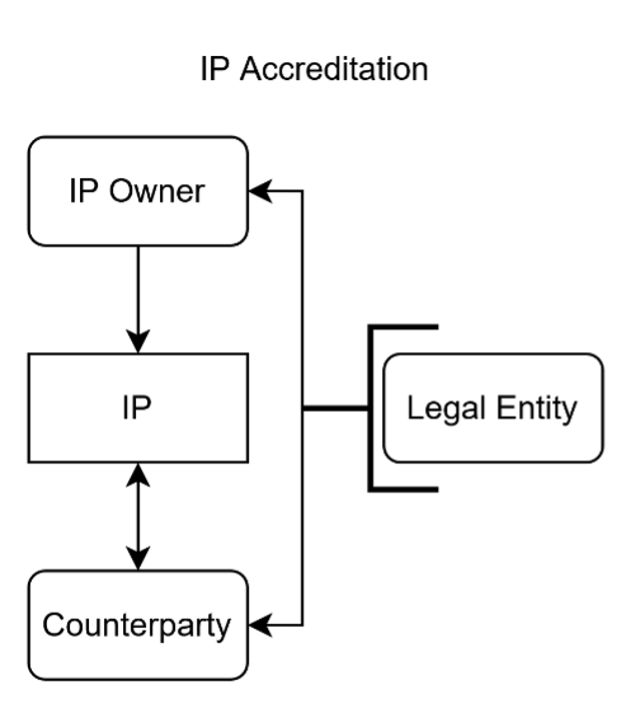
Statistical accreditation of IP unites these concepts into a system that describes what and how IP is synthesized using AI. Here, for each case of generated AI IP, the relative contribution of other IP used to generate it is estimated by the statistical accreditor. This presents a statistical pull model—in this case, IP is not necessarily owned by the AI platform hosting the AI tool (consider Retrieval-Augmented Generation, which is a technique that enables LLMs to retrieve and incorporate new information[44]), and creators create by introducing problem statements to AI tools and returning readouts. This is depicted in Figure 10, combining Figures 8 and 9. Remuneration would scale to the relative influence of owned IP on the AI output; however, the exact mechanism needs to be further explored.
Figure 10
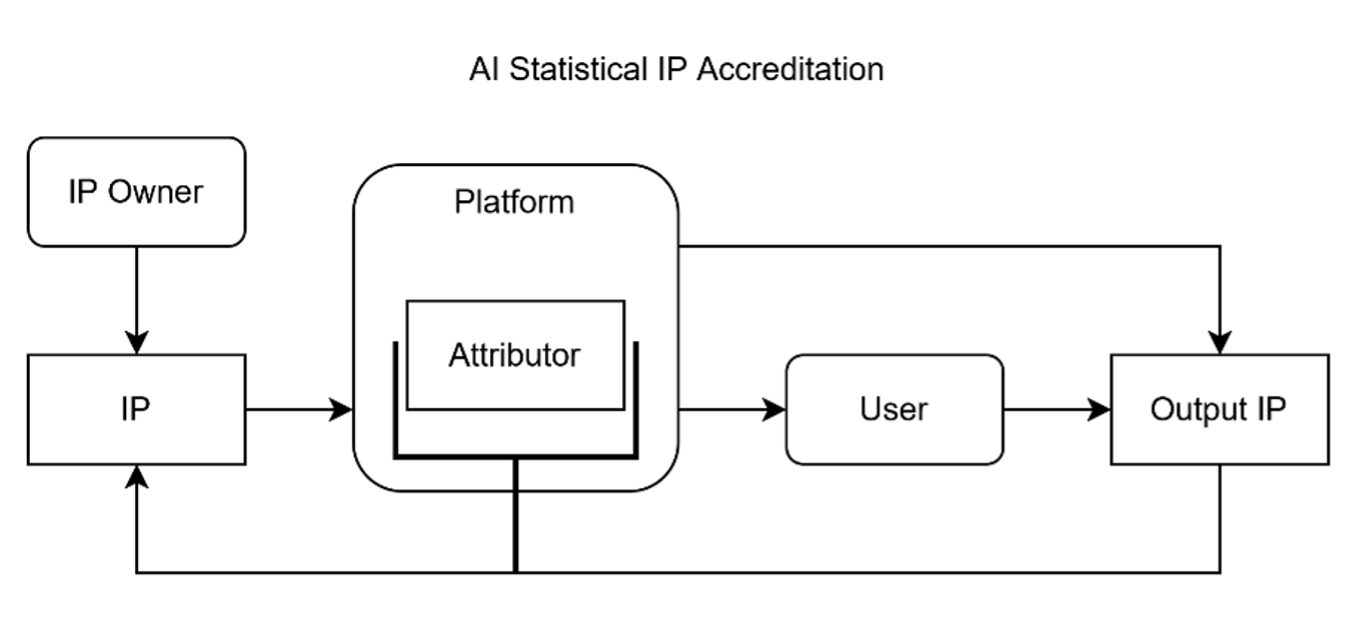
Statistical pull accreditation, combined with remuneration, provides a scalable way to reward creators whose IP most influences AI outputs.
While impact is a variable with multiple definitions, originality and alignment to public usage are two key vectors known to influence impact. Thus, this would promote the creation of novel IP and help solve the problem of AI-human alignment by affecting human activity to support the development of AI.
The design framework proposed here integrates statistical attribution, algorithmic explainability, and economic incentives into a unified model of ‘Statistical Intellectual Property’ (SIP). It rests on three principles: measurable provenance, autonomous remuneration, and incentive alignment.
This redefines economic growth as a function of human-AI co-alignment, where human creativity supplies the novelty required to expand AI’s problem-solving space, following models of human-AI symbiotic growth[45] and alignment economy frameworks.[46]
How to Enable Statistical IP
A branch of AI seeking to explain how AIs operate is called explainability. These use mathematical and statistical techniques to understand how sources and reasoning are leveraged and generated by AI systems to create outputs. To create statistical IP for the accreditation mechanism, explainability methods provide a valuable source of techniques.
As a brief review, ways to achieve explainability can be broadly divided into local and global explanations: local methods explain individual predictions, while global methods describe the overall logic of the model. For simpler models like linear regression or decision trees, this is straightforward; for high-dimensional, non-linear systems like neural networks, explainability requires approximation techniques that capture which inputs most influenced the output.
Among global methods, finding decision boundaries between decisions in an AI model characterizes it strongly and can be done by determining the minimal change to an input that would alter the outcome, called counterfactual explanation. The meaning behind these boundaries, or more general attributes, can be converted to something human-readable (e.g., “striped” or “animal”) by linking the abstract embeddings of deep networks to semantic meaning, using “Concept Activation Vectors”. Alternatively, the decision-making process itself can be reconstructed via causal and structural explainability methods.
Of local methods, one can learn how sensitive a model’s output is to small changes in input features using gradient-based methods, like Integrated Gradients and Gradient-weighted Class Activation Mapping (Grad-CAM). This is especially useful in image and text models. Alternatively, one may quantify the marginal contribution of each feature to a model’s prediction using such methods as Local Interpretable Model-agnostic Explanations (LIME) or SHapley Additive exPlanations (SHAP), which treat each feature as a ‘player’ contributing to the model’s overall performance. A subset of this is the Data Shapley approach,[47] which applies such reasoning to each datapoint rather than each feature. Tests of applying such techniques in a statistical pull context have been carried out to enable further research to make Shapley methods more tractable.[48]
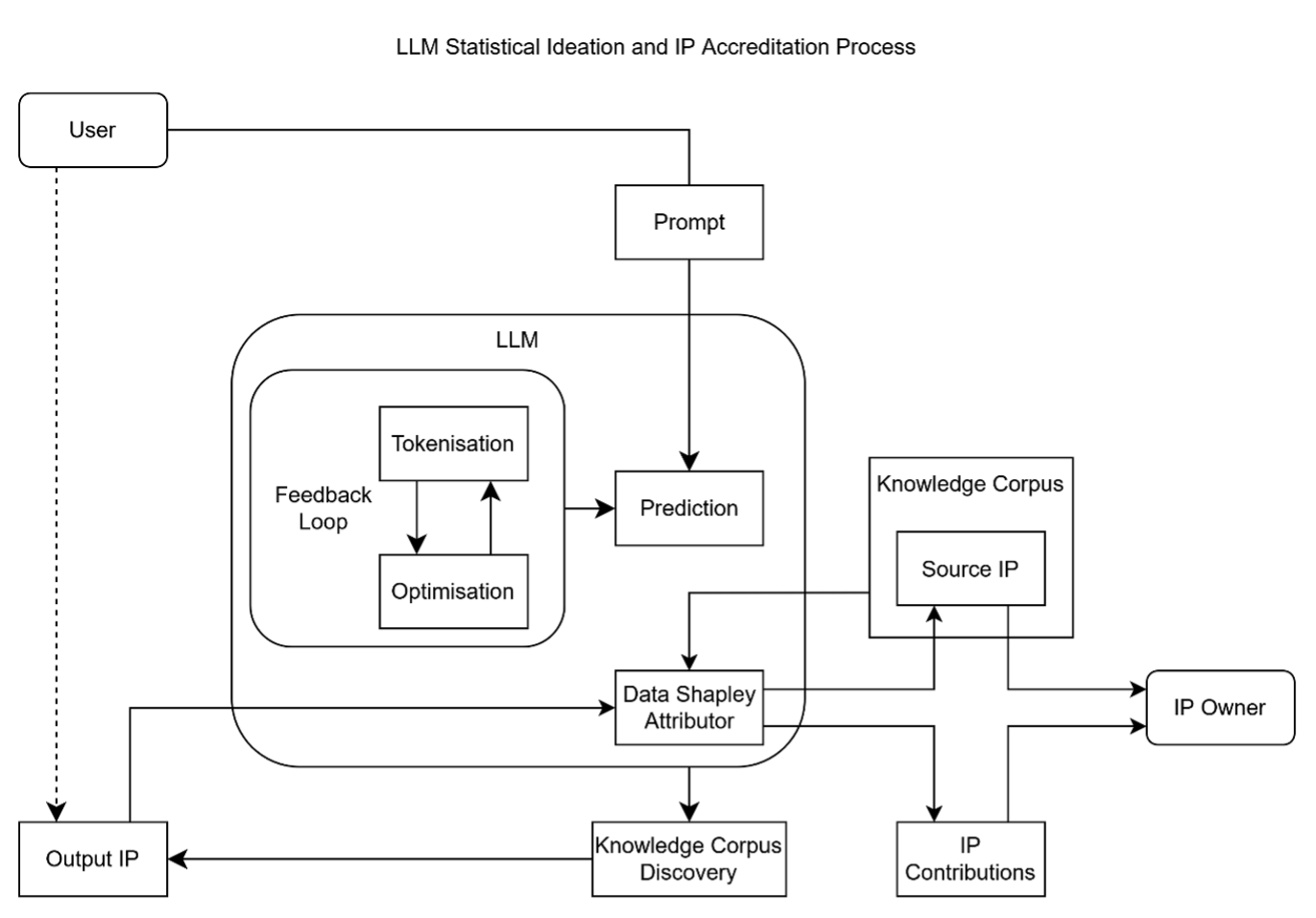
Data Shapley offers a cooperative-game framework for attributing credit among contributors, forming a quantitative basis for statistical remuneration of IP. Collectively, such methods enable quantifiable attribution of creative influence—linking an IP owner’s reward to the proportion of an AI output explained by their contribution. The tools from this field can be applied not only to explain but also to determine how much an owner of a given IP should be paid, given how much an AI output is “explained” by its use of their IP. This is depicted in Figure 11, embedding Figure 6 into Figure 10.
Figure 11
A final point is the implications of implementing such a system. This is proposed as a solution to the problem of AI’s lack of agency and lack of access to the universe as a whole, which makes its growth rely on novel information delivered by humanity. These are prerequisites for creativity. AGI is AI that is problem agnostic—to be problem agnostic is to be creative, since then solution finding can be derived through a constant of the self. As AI cannot be creative, AGI cannot be derived solely from it; however, it can be derived from the intersection of the human and AI ideation ecosystems.[49] Given our general intelligence and use of AI, from this definition, we must have a certain level of AGI already, subject to a lag of novel information entered into the AI ecosystem; this distinction and unity are represented in Figure 12 below.
Figure 12
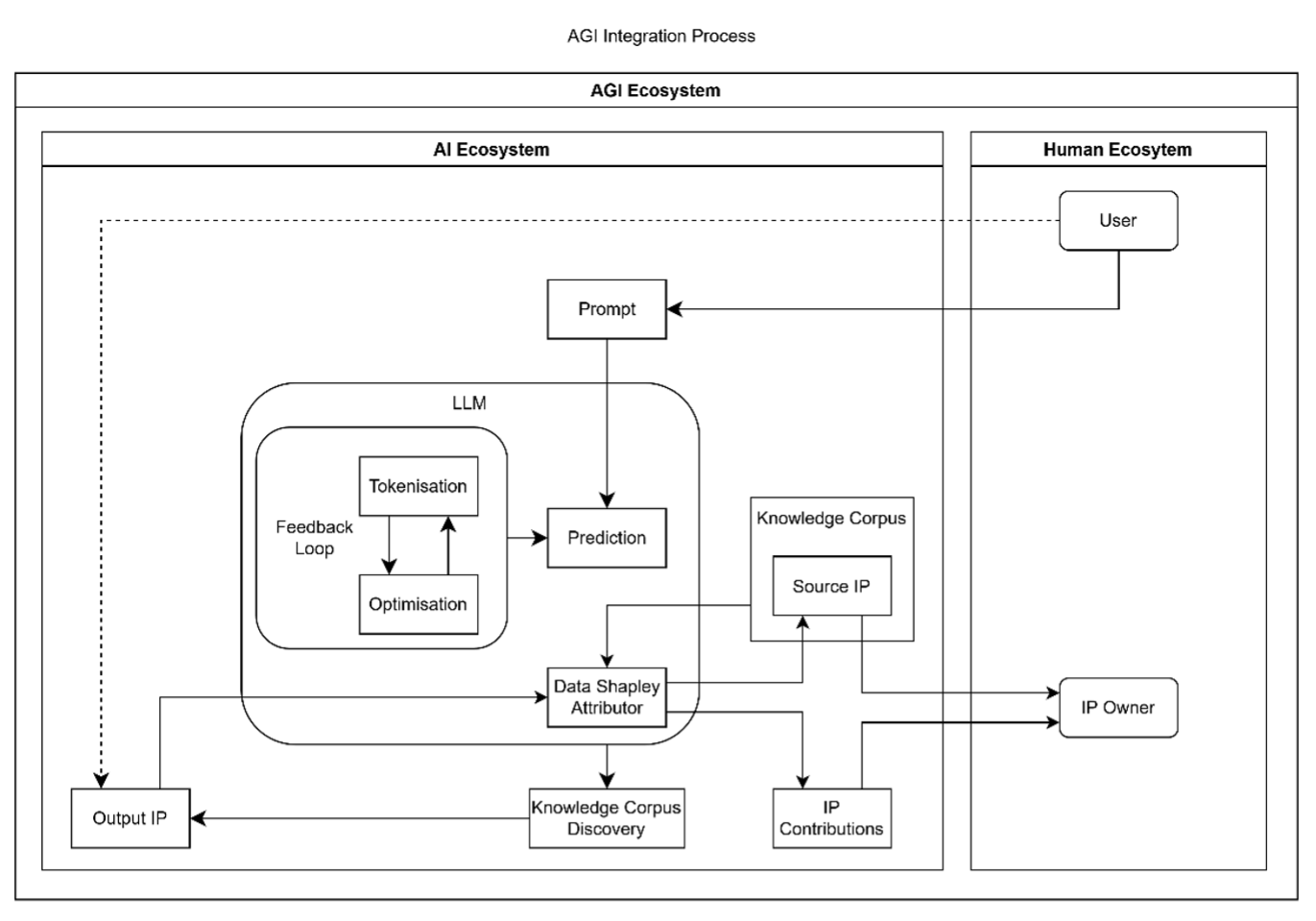
If this lag were reduced, then the intensity of AGI would increase to the point of fully autonomous and instant integration of human and AI ideation. Thus, the implementation of autonomous alignment systems, such as that proposed above, can be conceptually scaled along degrees of AGI attainment, as in Figure 13.
Figure 13

Next steps include developing six self-sustaining functions—contribution, provenance, usage, licensing, payment, and verification—each designed for practical and profitable implementation.
- Determining Contribution
- Proving Provenance
- Tracking Usage
- Clarifying Licenses
- Paying Sources
- Verification/Audit
Ideally, each function should also be developed in a manner that is societally self-reinforcing—this may mean profitability. Thus, the task would be to develop a successful business for each attribute and, from this stage, begin integrating business functions.
For policymakers, statistical IP enables new creative and fintech business models while modernizing legal infrastructure. By rewarding creativity as an alignment metric, it supports safe AI development without impeding innovation. It opens up a vast novel fintech sector to advance dividend payment mechanisms and space for the legal sector to update its approach to IP. It also has the benefit of producing an aligned criterion for a proposed AGI, since creativity, which would be the differentiating factor of AGI to AI, would have an outlet that integrates to human benefit. Thus, such a system would be a pillar to permit safe AI without needing to slow down its development.
Operationalizing this framework would require international governance similar to existing copyright collection societies or creative commons infrastructures, adapted for statistical traceability. Implementation could be coordinated via WIPO, OECD, or blockchain-based data markets to ensure transparent remuneration.
This framework positions humanity within a global creative economy aligned with AI progress—transforming AI from a source of displacement into a catalyst for collective advancement toward natural AGI.
By embedding creativity into a quantifiable, rewardable framework, we can reorient AI from a force of extraction to one of elevation. Statistical intellectual property thus becomes the foundation for a sustainable, symbiotic intelligence economy—one that rewards invention, preserves agency, and integrates AI into the creative fabric of humanity.
[1] Erik Brynjolfsson and Andrew McAfee, The Second Machine Age: Work, Progress, and Prosperity in a Time of Brilliant Technologies (New York: W. W. Norton & Company, 2014); James E. Bessen, AI and Jobs: The Role of Demand, NBER Working Paper No. 31152 (Cambridge, MA: National Bureau of Economic Research, 2023).
[2] Andreas Kaplan and Michael Haenlein, “Siri, Siri, in My Hand: Who’s the Fairest in the Land? On the Interpretations, Illustrations, and Implications of Artificial Intelligence,” Business Horizons 62, no. 1 (2019): 15–25.
[3] Luciano Floridi and Massimo Chiriatti, “GPT-3: Its Nature, Scope, Limits, and Consequences,” Minds and Machines 30, no. 4 (2020): 681–694.
[4] Pamela Samuelson, “Generative AI Meets Copyright,” Communications of the ACM 66, no. 7 (2023): 24–26.
[5] Jessica Litman, “Real Copyright Reform,” UC Irvine Law Review 8, no. 3 (2018): 961–987; Daniel J. Gervais, “The Machine as Author,” Iowa Law Review 108, no. 2 (2023): 205–257.
[6] Alain Rechtman, “AI, Creativity, and the Future of Work,” Harvard Business Review, June 2023; Mark A. Lemley and Bryan Casey, “Fair Learning,” Texas Law Review 98, no. 5 (2020): 1247–1290.
[7] OECD, “Intellectual property issues in artificial intelligence trained on scraped data,” OECD Artificial Intelligence Papers, No. 33 (2025), OECD Publishing, Paris.
[8] Madeleine Clare Elish and Tim Hwang, An AI Pattern Language: Reframing Fairness Debates, Data & Society Research Institute, 2020.
[9] LinkedIn Economic Graph, LinkedIn Workforce Report | United States | September 2025.
[10] International Labour Organization (ILO), World Employment and Social Outlook: May 2025 Update (Geneva: International Labour Office, 2025), 5.
[11] International Labour Organization, World Employment and Social Outlook (WESO), May 2025.
[12] World Economic Forum, Future of Jobs Report 2025.
[13] Erik Brynjolfsson, Bharat Chandar, and Ruyu Chen, “Canaries in the Coal Mine? Six Facts about the Recent Employment Effects of Artificial Intelligence,” working paper, Stanford Digital Economy Lab, August 26, 2025
[14] Jin Liu, Xingchen Xu, Yongjun Li, and Yong Tan, ‘Generate’ the Future of Work through AI: Empirical Evidence from Online Labor Markets, SSRN Electronic Journal.
[15] Kerstin Hötte, Melline Somers, and Angelos Theodorakopoulos, “Technology and Jobs: A Systematic Literature Review,” Technological Forecasting and Social Change 194 (2023): 122750.
[16] Daron Acemoglu and Pascual Restrepo, “Automation and New Tasks: How Technology Displaces and Reinstates Labor,” Journal of Economic Perspectives 33, no. 2 (Spring 2019): 3–30.
[17] Lauren Takahashi, Michael Kuwahara, and Keisuke Takahashi, “AI and automation: democratizing automation and the evolution towards true AI-autonomous robotics,” Chemical Science 16(35) (2025):15769-15780.
[18] Ajay Agrawal, Joshua Gans, and Avi Goldfarb, Power and Prediction: The Disruptive Economics of Artificial Intelligence (Boston: Harvard Business Review Press, 2022).
[19] Kate Crawford, Atlas of AI: Power, Politics, and the Planetary Costs of Artificial Intelligence (New Haven, CT: Yale University Press, 2021).
[20] Gary Marcus, Rebooting AI: Building Artificial Intelligence We Can Trust (New York: Pantheon Books, 2019), 43–47.
[21] Massimiliano Carnevale, Alberto Borghese, and Fabrizio Gemelli, “A Human-Centred Approach to Symbiotic AI,” AI Communications 37, no. 3 (2024): 285–298.
[22] Isaac Newton, De Quadratura Curvarum, in Principia Mathematica, ed. Andrew Motte (London: Printed for S. & J. S. Austen, 1729), 245.
[23] Gottfried Wilhelm Leibniz, Sämtliche Schriften und Briefe, Reihe VII: Mathematische Schriften, vol. 5: Infinitesimalmathematik 1674–1676, Berlin: Akademie Verlag, 2008, pp. 288–295.
[24] Karl Popper, The Logic of Scientific Discovery (London: Routledge, 2002 [1959]), 31–33.
[25] Thomas S. Kuhn, The Structure of Scientific Revolutions, 3rd ed. (Chicago: University of Chicago Press, 1996), 52–57.
[26] Sonali Uttam Singh and Akbar Siami Namin. “A Survey on Chatbots and Large Language Models: Testing and Evaluation Techniques.” Natural Language Processing Journal 10 (2025): 100128.
[27] John McCarthy, Marvin L. Minsky, Nathaniel Rochester, and Claude E. Shannon, “A Proposal for the Dartmouth Summer Research Project on Artificial Intelligence,” Dartmouth College, 1956.
[28] Frank Rosenblatt, “The Perceptron: A Probabilistic Model for Information Storage and Organization in the Brain,” Psychological Review 65, no. 6 (1958): 386-408.
[29] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, and Illia Polosukhin, “Attention Is All You Need,” Advances in Neural Information Processing Systems 30 (2017): 5998–6008.
[30] Emily M. Bender, Timnit Gebru, Angelina McMillan-Major, and Shmargaret Shmitchell, “On the Dangers of Stochastic Parrots: Can Language Models Be Too Big?” Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency (2021): 610–623.
[31] Pamela Samuelson, “Generative AI Meets Copyright,” Communications of the ACM 67, no. 2 (2024): 20–23.
[32] Shane Legg and Marcus Hutter, “Universal Intelligence: A Definition of Machine Intelligence,” Minds and Machines 17, no. 4 (2007): 391–444.
[33] Stuart Russell, Human Compatible: Artificial Intelligence and the Problem of Control (New York: Viking, 2019), 119–126.
[34] World Intellectual Property Organization (WIPO), Understanding Copyright and Related Rights, 3rd ed. (Geneva: WIPO, 2021), 8–12.
[35] Andres Guadamuz, “Do Androids Dream of Electric Copyright? Comparative Analysis of Originality in AI-Generated Works,” Intellectual Property Quarterly 2 (2017): 169–186.
[36] Luciano Floridi and Massimo Chiriatti, “GPT-3: Its Nature, Scope, Limits, and Consequences,” Minds and Machines 30 (2020): 681–694.
[37] James Boyle, The Public Domain: Enclosing the Commons of the Mind (New Haven: Yale University Press, 2008), 41–45.
[38] Rebecca Giblin and Cory Doctorow, Chokepoint Capitalism: How Big Tech and Big Content Captured Creative Labor Markets and How We’ll Win Them Back (London: Scribe, 2022), 164–168.
[39] Philippe Aghion and Peter Howitt, “A Model of Growth through Creative Destruction,” Econometrica 60, no. 2 (1992): 323–351.
[40] Joel Mokyr, “The Past and the Future of Innovation: Some Lessons from Economic History,” Research Policy (2018).
[41] Alexander Bleier, Beth L. Fossen, and Michal Shapira, “On the Role of Social Media Platforms in the Creator Economy,” International Journal of Research in Marketing 41, no. 3 (2024): 411–426.
[42] Alexander Bleier, Mark Heitmann, and Gerrit van Bruggen, “On the Role of Social Media Platforms in the Creator Economy,” International Journal of Research in Marketing 41, no. 2 (2024): 344–362.
[43] Peter Drahos, A Philosophy of Intellectual Property (Aldershot: Dartmouth Publishing, 1996), 101–106.
[44] Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela, “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks,” Advances in Neural Information Processing Systems 33 (2020): 9459–9474.
[45] Christian Callaghan, “Rethinking Growth and the Future of Work: The Alignment Economy as a General Theory of Human-Centered AI,” SSRN Electronic Journal (2025).
[46] Orlando Gomes, “The Human Capital–Artificial Intelligence Symbiosis and Economic Growth,” De Economist 173, no. 2 (2025): 187–213.
[47] Amirata Ghorbani and James Zou, “Data Shapley: Equitable Valuation of Data for Machine Learning,” Proceedings of the 36th International Conference on Machine Learning, 2019, https://proceedings.mlr.press/v97/ghorbani19c.html.
[48] Ruoxi Jia, David Dao, Boxin Wang, Frances Ann Hubis, Nick Hynes, Nezihe Merve Gürel, Bo Li, Ce Zhang, Costas Spanos, and Dawn Song, “Towards Efficient Data Valuation Based on the Shapley Value,” Proceedings of the 22nd International Conference on Artificial Intelligence and Statistics 89 (2019): 1167–1176.
[49] Yingxu Wang, Fakhri Karray, Sam Kwong, Konstantinos N. Plataniotis, Henry Leung, Ming Hou, Edward Tunstel, Imre J. Rudas, Ljiljana Trajkovic, Okyay Kaynak, Janusz Kacprzyk, Mengchu Zhou, Michael H. Smith, Philip Chen, and Shushma Patel, “On the philosophical, cognitive and mathematical foundations of symbiotic autonomous systems,” (2021), Faculty Publications, 3748.



